Panel regressions are often used when you observe the same unit repeatedly over time, like say, countries across several years, firms across financial quarters, or people across survey waves or census. Essentially, panel regressions help you separate “within-unit change over time” from “between-unit differences,” which usually makes your estimates more credible than a simple pooled regression. Here, we’ll walk you through what a panel regression analysis is, when you need to use them, and how our data analysis experts at The Research Data Experts offer panel regressions analysis help.
What are Panel Regressions?
A panel (or longitudinal) dataset has two dimensions: units and time. You typically index units by i = 1, …, N and time by t = 1, …,T.
A common panel regression model, therefore, looks something like this:
yit = β′xit + αi + εit
where yit is the outcome variable for a unit i at time t, xit is a set of predictors, β is a vector of coefficients, αi captures time-invariant unit-specific factors (basically unobserved heterogeneity), and εit is the idiosyncratic error factor.
Many applied regression models will often include a time effects factor (common shocks) as follows:
yit = β′xit + αi + λt + εit
here, λt captures the shocks that affect all units in the data within a given period, say factors like policies, global recessions, inflation, pandemics, and so forth. This is often referred to as a “two-way specification” and is a very common setup in panel regression models.
When do you need Panel Regressions?
Panel regressions analyses are typically the right choice when any of the following are true:
- Your data has repeated observations for the same units over time (an ID and a time variable).
- You suspect that stable, unobserved differences across units matter (institutions, geography, culture, firm quality, baseline ability).
- You want to estimate how changes in x relate to changes in y within the same unit over time.
- You want to reduce omitted variable bias coming from time-invariant confounders.
- Your research question is inherently longitudinal in nature (“what happens after…”, “how does a change in policy affect outcomes over time?”)
Thus, if your dataset is purely cross-sectional (one time point), panel regression models are not appropriate.
Fixed effects vs random effects in Panel Regressions
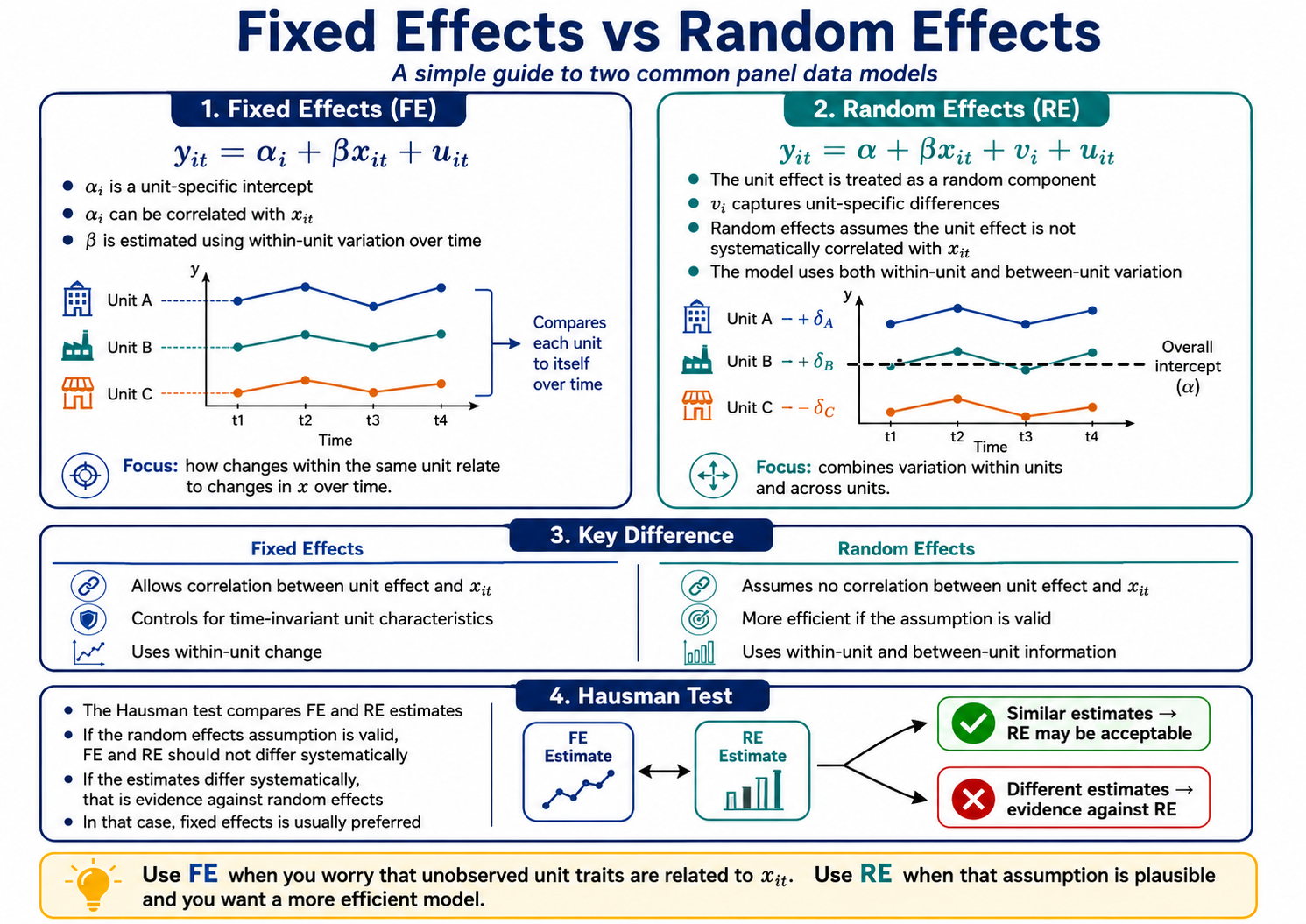
Fixed effects regression
A fixed effects regression treats αi as a unit-specific intercept that can be correlated with xit. The core idea is that you estimate β using only within-unit variation over time.
A helpful way to see this is with the “within transformation” as follows:
(yit − ȳi) = β′(xit − x̄i) + (εit − ε̄i)
This is why fixed effects regression removes all time-invariant factors (observed or unobserved). It also explains an important limitation of this model, as time-invariant predictors (like region or baseline geography) cannot be estimated in a standard fixed effects regression because they do not vary within a unit.
Random effects regression
A random effects regression treats the unit effect as a random component, as follows:
yit = β′xit + ui + εit
The key assumption here is that ui is not correlated with xit (informally: Cov(xit, ui) = 0). If that assumption holds, random effects regression can be more efficient and can estimate coefficients on time-invariant variables. If it does not hold, estimates can be biased.
The Hausman test (how to choose)
The Hausman test is commonly used to compare fixed effects regression and random effects regression. The intuition behind the test is if the random effects assumption is valid, then random effects and fixed effects should not differ systematically. However, if they do differ, that is evidence against random effects regression models.
In practice, while the Hausman test is a useful diagnostic, it is not a substitute for a clear research design. It should be interpreted alongside theory, measurement quality, and whether it is plausible that unobserved unit factors correlate with your predictors.
Doing Panel Regressions in Practice
Step 1: Structure your panel correctly.
You need two core variables: a unit identifier (id) and a time variable (time). You also need to verify the panel is correctly defined (no duplicate id-time rows unless your model supports it).
Step 2: Decide your baseline specification
Most panel regression models start with unit effects and often time effects (two-way). You also decide standard errors (clustered by unit is very common).
Step 3: Run fixed effects regression and/or random effects regression
Then, finally you compare results, run diagnostics, and stress-test your findings with sensible robustness checks.
At The Research Data Experts, we can run panel regression analyses in the platform (IDE) that matches your course, supervisor preferences, and deliverable format (Stata, R, SPSS, or mixed models where appropriate/ needed).
How The Research Data Experts can help
If you want your panel regressions analysis done cleanly and defensibly, we can support the entire process and not just the model run. That includes sourcing high-quality panel data, cleaning and harmonizing identifiers, merging and appending multi-source datasets, choosing the right specification (fixed effects regression vs random effects regression), running the Hausman test and other diagnostics appropriately, and producing report-ready tables, figures, and interpretation in clear language. Talk to us via email on info@theresearchdataexperts.com, or simply click the “Let’s Chat!” banner below to talk to one of our customer experience agents in real-time.